Expanding GPU usage in live video applications
Powerful GPUs (Graphics Processing Units) are more and more used in different industries to accelerate complex and time consuming processing tasks which were previously executed on the computer processor (aka CPU).
Coupled with a video I/O card, a GPU becomes a very effective live video processor used in various domains like computer graphics generation, video mixing, and signal processing.

On this last domain, new generations of GPU are developed and optimized specifically to speed up machine learning tasks, and they are now an essential part of any modern artificial intelligence infrastructure. Besides their initial graphics acceleration capabilities, GPUs now become general purpose processors thanks to the CUDA framework and GPU programming language.
However, moving large quantity of information in real time between an I/O card and the GPU is a challenge, and it often implies additional copies and delays.
What is GPUDirect RDMA?
RDMA stands for Remote DMA, or Remote Direct Memory Addressing.
The RDMA term initially defined a technology intended to networked computers communication, allowing direct data transfer between the memory buffers of two computers thanks to NICs supporting the RDMA technology over Converged Ethernet (RoCE) protocol.
Then, NVIDIA® used the same RDMA acronym to bring in peer-to-peer transfers capabilities to its different GPUDirect technologies intended to optimizing communication between NVIDIA GPUs and several types of 3rd party devices : network cards, computer storage, and video I/O cards.
GPUDirect RDMA is avalaible on Kepler-class GPUs since CUDA 5.0.
Benefits
As illustrated below, most of the benefits of using RDMA are link to the fact that data directly moves between devices without soliciting the CPU, host memory.
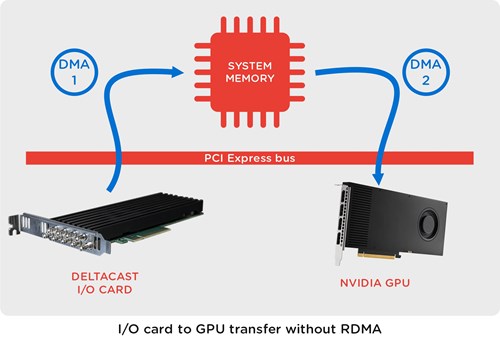
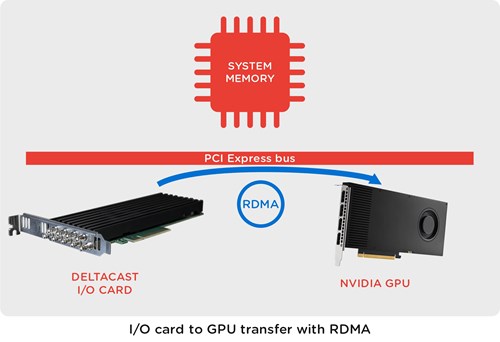
This concretely means :
- Cutting PCIe bandwidth consumption by a factor two
- Saving host memory buffers and host memory bandwidth (twice, as data were moved in and out)
- Saving CPU cycles
- Gain in latency
Basing on the fact that one 10-bit YUV 4K frame weights more than 22MB, then at 60p it means that one saves more than 2.5GB/s of host memory bandwidth and wins from 3.5 (PCIe Gen3 x8) up to 7 milliseconds (PCIe Gen2 x8) on the capture latency.
Availability
Since VideoMaster v6.20, all DELTACAST I/O cards and FLEX solutions support NVIDIA GPUDirect RDMA.
The RDMA technology is available under Linux, on x86_64 computer platforms as well as on some specific ARM64 devices like NVIDIA Jetson AGX Xavier and Orin.
GPUDirect RDMA comes with a series of requirements to be available on a target platform. Actually, peer-to-peer transfers require that the I/O card and the GPU share the same upstream PCI Express root complex. Additionally, the technology relies upon all physical addresses being the same from the different PCI devices point of view, making it incompatible with IOMMUs performing any form of translation other than 1:1. Address translation must hence be disabled or configured in pass-through mode.
RDMA for AI accelerated medical applications
DELTACAST specifically integrated the RDMA technology in the context of the NVIDIA Clara Holoscan AI development platform for medical applications.

Thanks to RDMA, video frames captured on the DELTACAST I/O card are immediately transferred to the GPU CUDA memory and made available to the downstream AI components of the GXF pipeline.
RDMA in the opposite direction allows to send back to the cable an enhanced version of the video produced on the GPU, or some overlay to be mixed and composited with the input feed in real-time on the DELTACAST card itself.





